The Unroll.me Data That Uber Bought Probably Isn't That Anonymous
As was to be expected, a recent New York Times article about Uber has gotten the internet into an uproar over how Uber conducts its business. What's strange, however, is that while much of the internet's displeasure has been focused on Uber (and reading the article points out several aggressive and probably borderline unethical actions by the company), the biggest casualty from this story might not be Uber at all. Instead, another company, Slice Technologies, owner of a popular inbox decluttering service Unroll.me, was revealed to have sold receipt data from Uber's competitor Lyft to Uber, in a supposedly anonymized fashion.
I personally don't think that Slice's particular defenses (we told you we do this and everyone else does it) are particularly compelling. The former depends on a Terms of Service no human being is actually reading, and the latter isn't quite true: the closest analogy I have seen would be Google mining its own data (in its apps and services) to monitor employees of competitors like Apple and Facebook. But that is an issue for another day.
My problem with this whole saga is the fact that the information Slice sold really isn't that anonymous.
Location data might be enough
Let's suppose for a second that Slice did what it thought was due diligence and removed the names from every receipt. From the articles that I've read, that is essentially the extent to which the data was anonymized and sold to Uber.
Unroll.me, a free service to unsubscribe from email lists, can scour people’s inboxes for receipts from services like Lyft and then sell the information to companies like Uber. The data is anonymized, meaning individuals’ names are not attached to the information, and can be used as a proxy for the health of a rival.
It's possible that Slice also protected some of the location data, but a) that's very much unclear from its own privacy policy, and b) If they sold receipt-level data, it's possible both that Uber wanted that location data to keep track of Lyft and that the data is there anyways. At the very least, nothing in Slice's privacy policy prohibits this, and it's very likely they make as much of the individual receipt-level information available as possible.
This is a problem, since a Lyft receipt looks like this:
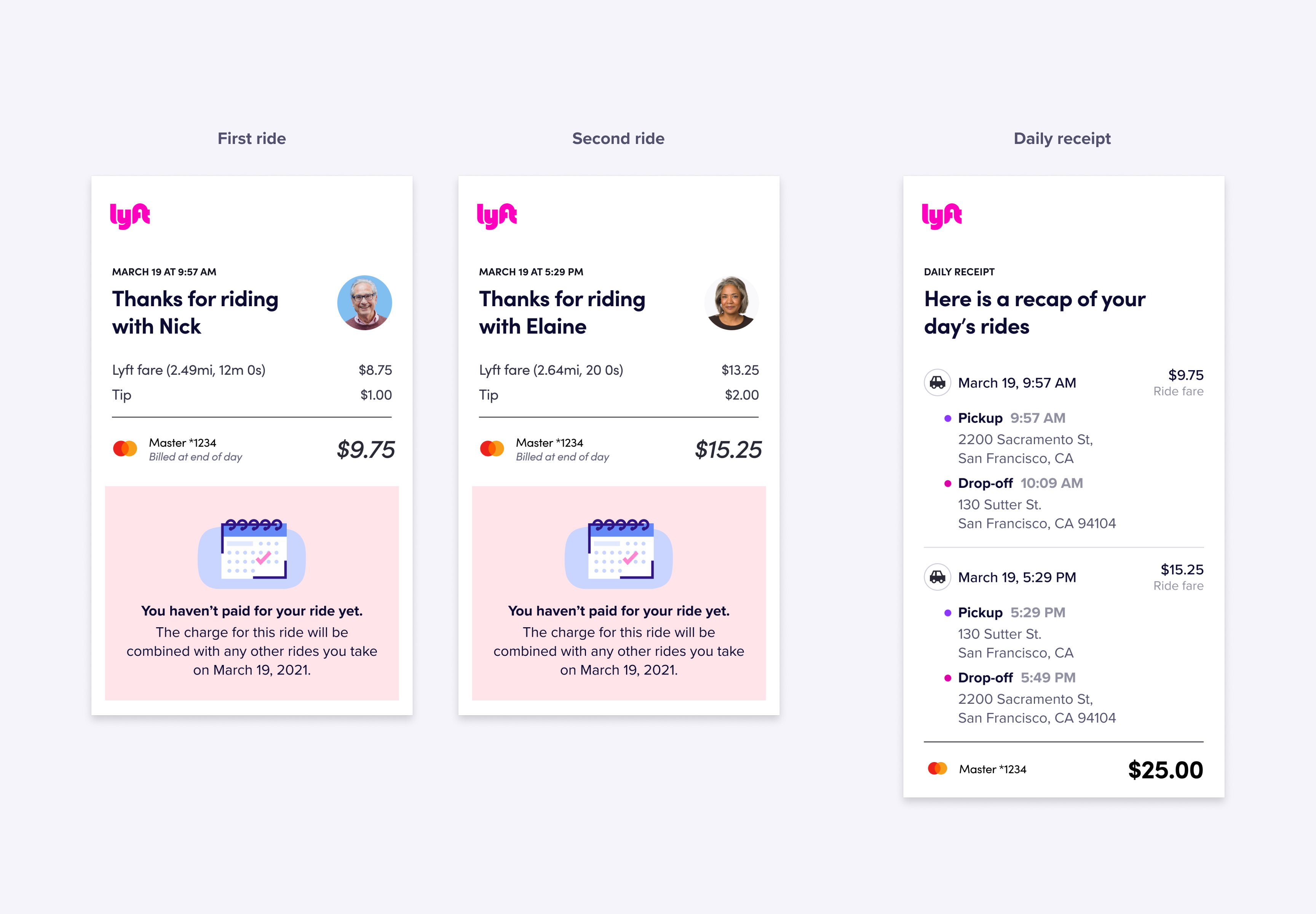
If the reporting around these data sales is true, then what we assume is that all of the information in the receipt above, sans the customer's name, were sold to Uber. That means the last 4 of the credit card, the pickup, and the dropoff, would all be information that Uber could effectively parse. In the abstract, missing the names might be an effective method for eliminating personally identifiable information that would allow someone to trace individual trips back to an actual person. That is to say, this it's difficult to take that kind of receipt data and expose individual identities from just that database alone.
The problem is that Uber has another pretty much identical database which can be used to reveal these receipt-level identities.
How to take "anonymous" data and find identities if you're Uber
- Take your own users' data, specifically any saved addresses (for example for Home or Work)
- In addition to this, find for each user their most commonly used addresses/GPS coordinate region (say, within 50 feet) both for pickup and dropoff
- Since the Slice data exists also at the user level, do the same thing for receipts you get for each distinct customer
- If Slice gives you the last 4 of the credit cards for each receipts, compare those with your internal data as well
- Use the information from steps 1-4 (and information about when rides were requested as well) to match up users
- Now you have information on which of your Uber riders use Lyft, and their names.
There are, of course, many caveats to this process. For starters, it's not very well defined since the objective here was not to fully flesh out the exact process by which to match up this supposedly anonymous data with Uber's own data, but rather to point out the general direction by which it could be done. It's also possible that Slice Technologies is better about data privacy than the articles claim, since they might simply aggregate data up at a level that makes it harder to tell who individual users are. Moreover, it's possible that Slice neither provided nor Uber requested that level of granularity, though I am more skeptical about the latter case and nothing within Slice's privacy policy actually rules that out (and indeed reserves the right to sell email messages). And finally, even given all this information, you probably can't get a 100% match between Lyft and Uber users (though very good rates are not out of the question).
Do a better job of protecting user privacy
Nonetheless, the biggest problem was simply the claim that removing people's names from this receipt level data was sufficient to anonymize the information. Perhaps in the abstract this is true, but when everything else about the receipt information is available, it's not that hard to figure out a name. Indeed, Uber would be far from the only company that could do this: any e-commerce business that stores addresses or tracks locations could use this level of data to find the identities of Lyft users. Given all of the potential touchpoints available from these receipts (and other touchpoints Slice has, including but not limited to device IDs, geographical location, times of purchase, amount of purchase, and last 4 of the credit card), to call this data anonymous simply because names were removed is simply wrong.
Data and databases don't exist simply in the abstract. When considering how to securely release or anonymize your data, not accounting for the data that the party you're selling to might have is one surefire way to leak data you didn't want to reveal in the first place. At the very least, companies should be revealing as little data as possible to third parties if they truly care about protecting user privacy. Barring that, aggregating the data or adding random noise to the user-level data is imperative if you actually care about obscuring personally identifiable information.
Also, if you haven't already, you should probably delete your Unroll.me account.